|
双核心至强服务器平台测试-woodcrest篇
在上篇文章中(双核心至强服务器平台测试-dempsey篇),我们拿2颗双核至强处理器平台(代号dempsey)与2颗单核至强平台(代号nocona)做了一下对比,dempsey以双核心,高主频的优势,完全胜出单核心,由此可看到双核的优势自然是不言而喻的。此篇文章我们会拿Intel在dempsey之后的另一款代号为woodcrest的双核至强平台做对比,Intel称这是他们的秘密武器,有了这些,和对手AMD比拼性能、功耗,效率,AMD彻底的败下阵来。
为什么woodcrest的性能会这么强劲
为什么woodcrest的功耗会这么低
为什么woodcrest的改变会是这么大
首先我们还是要介绍一下代号为woodcrest至强处理器的重要特征
Woodcrest至强处理器采用Intel新一代的Core微架构,Intel桌面核心、移动核心和服务器核心都将采用这一统一架构,新的架构在性能/功耗比上
拥有十分突出的优势。
其中包括5大创新特性,分别是:宽位动态执行、智能功率特性、高级智能高速缓存、智能内存访问以及高级数字媒体增强。通过这5个方面的增强和改进,处理器真正做到了低功耗高性能,同时兼顾双核、多媒体应用等最新趋势,彻底走出了之前一味追求频率导致恶果的怪圈。
Intel宽位动态执行(Intel Wide Dynamic Execution)
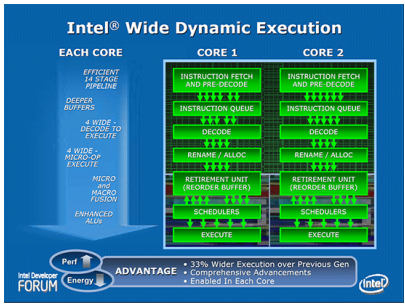
当今衡量一款处理器的性能水平,已经不能再单纯的以频率的高低考量,而是更强调“每瓦特性能”,也就是所谓的能效比。性能=频率×每个时钟周期的指令数
是Intel新提出的对性能的创新理解,Intel宽位动态执行的出发点,就是为了提升每个时钟周期完成的指令数升,从而显著改进执行能力和能效。
Intel酷睿微架构拥有4组解码器,相比上代的Pentium
M架构拥有3组可多处理一组指令,简单讲,每个内核将变得更加宽阔,这样每个内核就可以同时获取、分配、执行和退回多达4条完整的指令。
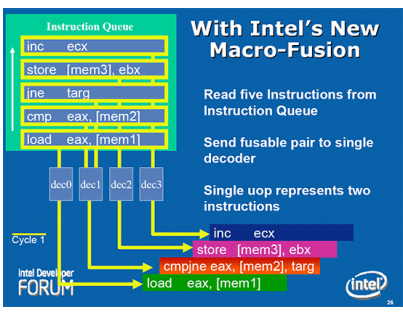
Intel酷睿微体系结构在提升每个时钟周期的指令数方面做了很多努力,例如新加入宏融合(Macro-Fusion)技术,它可以让处理器在解码的同时,将同类的指令融合为单一的指令,这样可以减少处理的指令总数,让处理器在更短的时间内,以更低的功率处理更多的指令。为此Intel酷睿微体系结构也改良了ALU(Arithmetic
Logic Unit)部份以支持宏融合技术。
Intel智能功率能力(Intel Intelligent Power Capability)
Intel智能功率能力,可以进一步降低功耗,优化电源使用,从而为服务器、台式机和笔记本电脑提供个更高的每瓦特性能。新一代处理器在制程技术方面做出优化,采用了先进的65nm
Strained Silicon技术、加入Low-K
Dielectric物质及增加金属层,相比上代90nm制程减少漏电情况达1000倍。
值得注意的是,Intel加入了超精细的逻辑控制机能独立开关各运算单元,具体来讲,酷睿微体系结构采用先进的功率门控技术,来充分利用该微架构的超精细逻辑控制。以往功率门控技术实现起来十分困难,因为元件开关过程需要消耗一定的能源,而且由休眠到恢复工作也会出现延迟,但Intel酷睿微体系结构已经解决这些问题。
通过该特性,可以智能的打开仅仅是当前需要的子系统,而其他部分则处于休眠状态,这样将大幅降低处理器的功耗及发热。
Intel高级智能高速缓存(Intel Advanced Smart Cache)
以往的多核心处理器,其每个核心的二级缓存是各自独立的,这就造成了很多应用下,二级缓存不能够被充分利用,并且两个核心之间的数据交换路线也更为冗长,必须要通过共享的FSB和北桥来进行数据的交换,负担很大,严重影响了处理器工作效率。
而Intel酷睿微结构体系结构,采用了共享二级缓存的做法,有效的加强了多核心架构效率。这样的好处是,两个核心可以共享缓存内部的数据计算据结果,而不是通过FSB和北桥再进行外围的交换,大幅增加了缓存的命中率。
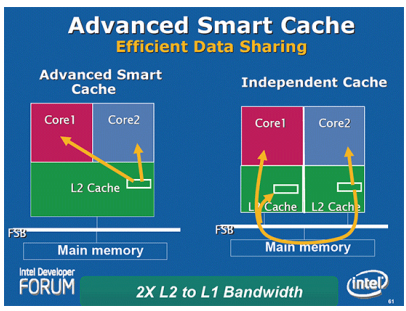
Intel高级智能高速缓存还有其他方面的优势,每个核心都可以动态支配100%的全部缓存。例如某一个内核当前对缓存的利用很低,那么另一个内核就可以动态的增加占用二级缓存的比例。Intel酷睿微体系结构可以把其中的一个内核关闭以降低功耗,但却可以保持全部缓存在工作状态,当然也可以根据需求关闭掉部分缓存来降低功耗。
这样可以降低缓存的命中失误,减少数据延迟,改进处理器效率,增加绝对性能和每瓦特性能。
Intel智能内存访问(Intel Smart Memory Access)
Intel智能内存访问是另一个能够提高系统性能的特性,他可以通过隐藏内存延迟,来优化内存子系统之外的数据带宽使用率。Intel智能内存访问能够预测系统的需要,从而智能的提前载入或预取数据,反映到用户的直接使用体验上,就是大幅提高了执行程序的效率。
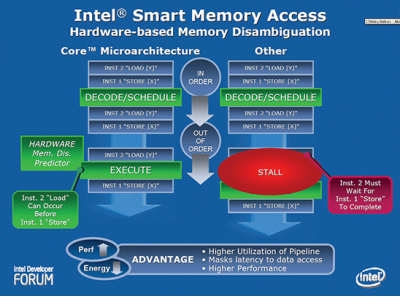
以前我们要从内存中读取数据,就需要等待处理器完成前面的所以指令后才可以进行,这样的效率显然是低下的。而Intel酷睿微体系结构中加入一项名为内存消歧的能力,它可以对内存读取顺序做出分析,智能、预测性的装载下一条指令所需要的数据,这样能够减少处理器的等待时间减少闲置,同时降低内存读取的延迟,而且它可以侦测出冲突并重新读取正确的资料及重新执行指令,保证运算结果不会出错误,大大提高了执行效率。
Intel高级数字媒体增强(Intel Advanced Digital Media Boost)
上面提到了性能=频率×每个时钟周期的指令数
这个新概念,而Intel高级数字媒体增强也同样是为了提高每个时钟周期的指令数而诞生,它可以提高SIMD流指令扩展指令(SSE/SSE2/SSE3)的执行效率。之前的处理器需要两个时钟周期来处理一条完整指令,而Intel酷睿微体系结构则拥有128bit的SIMD执行能力,一个时钟周期就可以完成一条指令,效率提升明显。
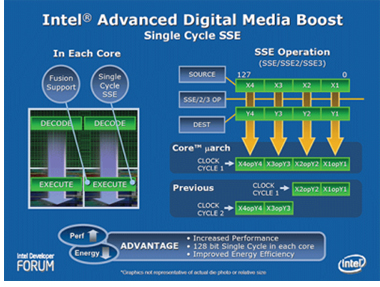
当前SSE指令集已经十分普遍地用于主流的软件中,包括绘图、影像、音频、加密、数学运算等用途,单周期128Bit SIMD处理器能力以频率以外的方法提升性能,令处理器拥有高能源效益表现。
Woodcrest至强处理器介绍
Woodcrest采用65nm制程,处理器接口为LGA771,频率从1.6G~3.0G,支持1333MHz前端总线,而L2Cache数目将会为4MB,并支持双核心共用L2Cache以减少使用FSB作交换,而最高功耗将不超过80W,请注意,woodcrest处理器不支持超线程技术。
以下为Woodcrest至强处理器参数表
| 处理器 |
主频 |
核心数 |
缓存L2 |
前端总线 |
最大功耗 |
封装方式 |
| 至强5160 |
3.0G |
2 |
4M |
1333MHZ |
80W |
LGA771 |
| 至强5150 |
2.66G |
2 |
4M |
1333MHZ |
65W |
LGA771 |
| 至强5148LV |
2.33G |
2 |
4M |
1333MHZ |
40W |
LGA771 |
| 至强5140 |
2.33G |
2 |
4M |
1333MHZ |
65W |
LGA771 |
| 至强5130 |
2.0G |
2 |
4M |
1333MHZ |
65W |
LGA771 |
| 至强5120 |
1.86G |
2 |
4M |
1066MHZ |
65W |
LGA771 |
| 至强5110 |
1.6G |
2 |
4M |
1066MHZ |
65W |
LGA771 |
一、测试平台说明:
主板:S5000PSL
CPU: 2*Xeon5160(3.0G/1333Mhz/4M)
内存:FB-dimm 512M/DDR533*4
硬盘:SATA2 160G
电源:EPS 500W
操作系统:windows server 2003 sp1
windows xp sp2
驱动: 芯片组:intel_chipset_7.3.0.1012
网卡:intel-lan_msft_v10.4_whql
测试使用软件:
CPU 检测软件: CPU-Z 1.36
单线程运算性能测试:SuperPI
CPU运算测试:Sisoftware SandraPro 2007
3D渲染测试: 3D max 7
视频压缩转换 WinAVI 7.6
一、系统显示与CPU-Z 1.36 检测结果
如下图:
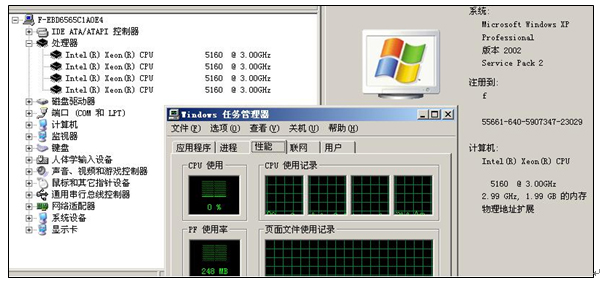
woodcrest处理器不支持超线程技术,系统显示4颗真实的处理器。
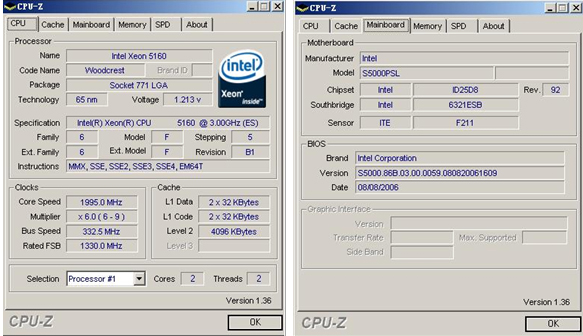
Xeon5160为woodcrest最高主频的处理器,3.0G,65nm,支持EM64T,此平台采用了S5000PSL
二、SuperPI 104万位单线程运算测试
数据如下: (时间越短越快)
| |
Woodcrest5150(xeon3.0G) |
Dempsey5080(3.73G) |
Xeon3.2G(nocona) |
| 时间(单位:秒) |
18秒 |
36秒 |
43秒 |
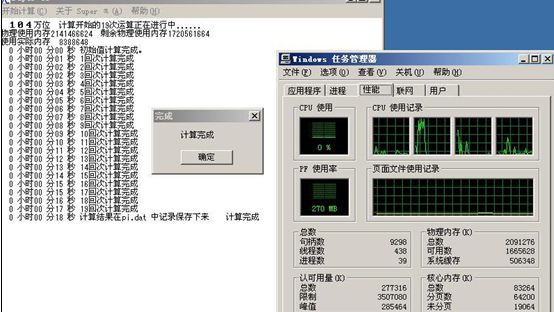
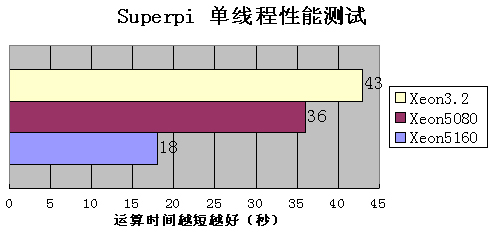
从Woodcrest至强开始,主频的高低不在是衡量处理器性能的唯一标准。Xeon5160能以大幅度的优势领先,全因为采用了Core的架构。
三、使用Sisoftware SandraPro 2007测试处理器运算性能
浮点和整数运算方面

多媒体运算性能
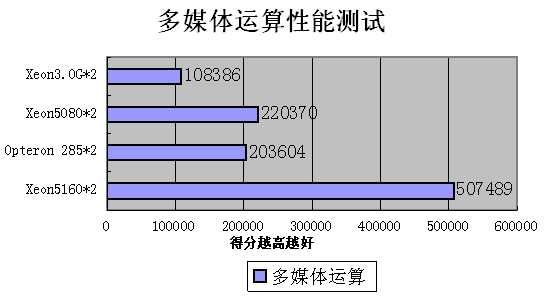
无论运算方面,还是多媒体方面,都大幅领先,均优于AMD的Opteron285平台。
内存带宽测试
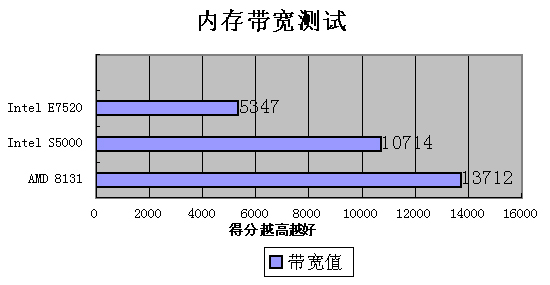
此项测试中,AMD平台领先。由于AMD处理器天生的特性,内置内存控制器,使处理器与内存之间可以直接进行数据交换。在这里我们还是要对Intel5000采用的FB-dimm内存技术是肯定的,从E7520到S5000,带宽提升了一倍。
四 3D MAX 7 渲染测试
测试中我们选取了由SPEC公司出品的For
max的插件,安装在MAX7上,只要我们运行批处理文件,测试就会开始,同时我们需要做的是记录所用的时间。
测试共分4个场景,我们分别对Xeon5160、Xeon5080和Xeon3.0G平台做了测试。然后记录的结果对比如下:

主频高达3.73G的Dempsey5080,也不敌3.0G的Woodcrest5160,差了将近一倍的性能。经常渲染的朋友们注意了,Xeon51XX系列将是你们不二的选择。
五 WinAVI 视频转换测试
WinAVI介绍
WinAVI Video Converter 是专业的视频编、解码软件。该软件支持包括AVI、MPEG1/2/4、VCD/SVCD/DVD、DivX、XVid、ASF、WMV、RM在内的几乎所有视频文件格式。自身支持VCD/SVCD/DVD烧录。支持AVI->DVD、AVI->VCD、AVI->MPEG、AVI->MPG、AVI->WMV、DVD->AVI、及视频到AVI/WMV/RM的转换。
在此,我们找到一部DVD电影,把VOB格式转换为AVI格式,两个平台所用时间:
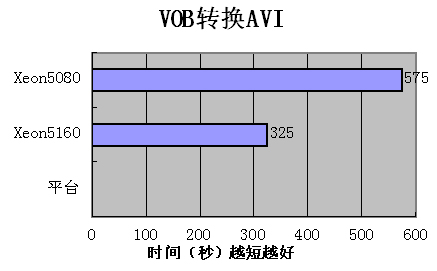
然后我们又把AVI格式转换为VOB格式的DVD,对比两个平台所花时间
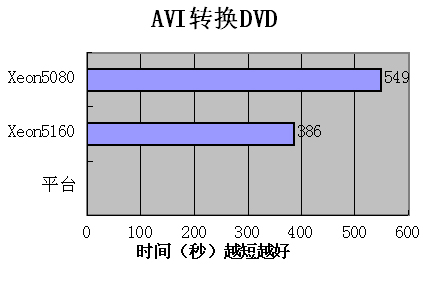
Xeon5160平台以优异的性能,大幅领先Xeon5080平台,接近有一倍的性能提升.
六、小结
Woodcrest,让我们对新一代双核心至强有了一个全新的认识,不在单纯的拿主频对比性能,最高80W的功耗,使我们在测试当中,完全感觉不到处理器热量。就整体表现的性能来讲,Xeon5160已经是我们测试双路平台中最强的性能了,根据多方网站加之我们的实际测试的结果,双颗Xeon5160加之4通道的FB-dimm内存搭配起来,可以说,是世界最强的双路服务器了。特别是3D行业,后期的渲染,视频压缩转换,这些极耗处理器资源的应用,Woodcrest表现给我们的是惊喜。需要特别提出的是,我们在测试完成后,小测了一下Woodcrest
最低型号的Xeon5110,主频1.6G,多方面的应用性能几乎和Nocona
Xeon3.0G两颗一致。试想一下,一个1.6G和两个3.0G一致。说明两个问题:一、双核的能效真的是非常高的。二、core架构的优势再次体现出来,低频率,高性能,低功耗。
还需要说明一点的是,Woodcrest处理器不支持Intel超线程技术,Intel告诉我们的是:超线程会在以后适当的时候出现,Woodcrest不需要超线程,因为它的性能已经很高了。
同时为了使用户用到更好产品,我们也推出了超低价位的成熟机型:

英腾T202-4M
参数如下:
双路双核Xeon®塔式服务器
标准配置
Xeon 5110*1(1.6G)
FB-DIMM 1G
160G SATAII
400W服务器电源
配置特点:
配合Core架构的双核至强处理器,支持多线程多任务模式.适合FB-DIMM内存,提供一个高可选的内存解决方案.支持RAID功能,满足系统对硬盘安全性的要求,集成双千兆服务器网卡,支持链路汇聚以及绑定冗余功能,适合多种应用需求。
最大优点:低功耗,高性能,高效率,性能可比双至强3.0G
适用于:
数据存储、数据库应用、高性能计算、计算
机集群等领域,是数据中心建设、电子政务、企业信息化建设、游戏网站、宽带网络建设、校园主干网建设等方面
|